RankTune
Overview
RankTune is a pseudo-stochastic data generation method for creating fairness-aware ranked lists using the fairness concept of statistical parity. Included in the RankTune module, it creates ranking(s) based on the phi representativeness parameter. When phi = 0 then the generated ranked list(s) does not represent groups fairly, and as phi increases groups are represented more and more fairly; thus phi = 1 groups are fairly represented. RankTune uses a pseudo-random process to generate fairness-aware ranked data. RankTune can generate ranked data from user provided group sizes, from existing datasets, along with producing relevance scores accompanying the ranked list(s).
Usage
RankTune can be utilized through four function interfaces.
Using Group Sizes
RankTune can be used to generate ranking(s) from group_proportions, a numpy array with each group's proportion of the total items,num_items, by using the GenFromGroups() function.
Usage:
import FairRankTune as frt
import numpy as np
import pandas as pd
from FairRankTune import RankTune, Metrics
#Generate a biased (phi = 0.1) ranking of 1000 items, with four groups of 100,
# 200, 300, and 400 items each.
group_proportions = np.asarray([.1, .2, .3, .4]) #Array of group proportions
num_items = 1000 #1000 items to be in the generated ranking
phi = 0.1
r_cnt = 1 #Generate 1 ranking
seed = 10 #For reproducibility
ranking_df, item_group_dict = frt.RankTune.GenFromGroups(group_proportions,
num_items, phi, r_cnt, seed)
#Calculate EXP with a MinMaxRatio
EXP_minmax, avg_exposures_minmax = frt.Metrics.EXP(ranking_df,
item_group_dict, 'MinMaxRatio')
print("EXP of generated ranking: ", EXP_minmax,
"avg_exposures: ", avg_exposures_minmax)
Output:
EXP of generated ranking: 0.511665941043515 avg_exposures: {0: 0.20498798214669187, 1: 0.13126425437156242, 2: 0.11461912123646827, 3: 0.10488536878769836}
Using an Existing Dataset
RankTune can be used to generate ranking(s) from item_group_dict, a dictionary of items where the keys are each item's group by using the GenFromItems() function.
Usage:
import FairRankTune as frt
import numpy as np
import pandas as pd
from FairRankTune import RankTune, Metrics
#Generate a biased (phi = 0.1) ranking
item_group_dict = dict(Joe= "M", David= "M", Bella= "W", Heidi= "W", Amy = "W",
Jill= "W", Jane= "W", Dave= "M", Nancy= "W", Nick= "M")
phi = 0.1
r_cnt = 1 #Generate 1 ranking
seed = 10 #For reproducibility
ranking_df, item_group_dict = frt.RankTune.GenFromItems(item_group_dict,
phi, r_cnt, seed)
#Calculate EXP with a MinMaxRatio
EXP_minmax, avg_exposures_minmax = frt.Metrics.EXP(ranking_df,
item_group_dict, 'MinMaxRatio')
print("Generated ranking: ", ranking_df)
print("EXP of generated ranking: ", EXP_minmax,
"avg_exposures: ", avg_exposures_minmax)
Output:
Generated ranking: 0
0 Nick
1 Dave
2 David
3 Joe
4 Nancy
5 Jane
6 Jill
7 Amy
8 Heidi
9 Bella
EXP of generated ranking: 0.5158099476966725 avg_exposures: {'M': 0.6404015779112127, 'W': 0.33032550440724917}
Generating Scores With the Ranking
Both GenFromGroups() and GenFromItems() contain sibling functions; respectively, ScoredGenFromGroups() and ScoredGenFromItems() that also generate relevance scores alongside the produced ranking(s). Scores are generated from either a normal or uniform distribution by setting the score_dist parameter to either normal or uniform.
For generating from group proportions use ScoredGenFromGroups() as follows:
import FairRankTune as frt
import numpy as np
import pandas as pd
from FairRankTune import RankTune, Metrics
#Generate a biased (phi = 0.1) ranking of 1000 items, with four groups of 100,
# 200, 300, and 400 items each.
group_proportions = np.asarray([.1, .2, .3, .4]) #Array of group proportions
num_items = 1000 #1000 items to be in the generated ranking
phi = 0.1
r_cnt = 1 #Generate 1 ranking
seed = 11 #For reproducibility
score_dist = "uniform"
ranking_df, item_group_dict, scores_df = frt.RankTune.ScoredGenFromGroups(group_proportions,
num_items, phi, r_cnt, score_dist, seed)
#Calculate EXP with a MinMaxRatio
EXP_minmax, avg_exposures_minmax = frt.Metrics.EXP(ranking_df,
item_group_dict, 'MinMaxRatio')
print("EXP of generated ranking: ", EXP_minmax,
"avg_exposures: ", avg_exposures_minmax)
Output:
EXP of generated ranking: 0.5218433930014378 avg_exposures: {0: 0.20212221456603452, 1: 0.13273063123258025, 2: 0.11380909457280128, 3: 0.10547614225010409}
For generating from existing items use ScoredGenFromItems() as follows:
import FairRankTune as frt
import numpy as np
import pandas as pd
from FairRankTune import RankTune, Metrics
#Generate a biased (phi = 0.1) ranking
item_group_dict = dict(Joe= "M", David= "M", Bella= "W", Heidi= "W", Amy = "W",
Jill= "W", Jane= "W", Dave= "M", Nancy= "W", Nick= "M")
r_cnt = 1 #Generate 1 ranking
seed = 10 #For reproducibility
phi = 0.1
score_dist = "uniform"
ranking_df, item_group_dict, score_df = frt.RankTune.ScoredGenFromItems(item_group_dict,
phi, r_cnt, score_dist,seed)
#Calculate EXP with a MinMaxRatio
EXP_minmax, avg_exposures_minmax = frt.Metrics.EXP(ranking_df,
item_group_dict, 'MinMaxRatio')
print("Generated ranking: ", ranking_df)
print("Generated scores: ", score_df)
print("EXP of generated ranking: ", EXP_minmax,
"avg_exposures: ", avg_exposures_minmax)
Output:
Generated ranking: 0
0 Nick
1 Dave
2 David
3 Joe
4 Nancy
5 Jane
6 Jill
7 Amy
8 Heidi
9 Bella
Generated scores: 0
0 0.771321
1 0.760531
2 0.748804
3 0.633648
4 0.498507
5 0.224797
6 0.198063
7 0.169111
8 0.088340
9 0.020752
EXP of generated ranking: 0.5158099476966725 avg_exposures: {'M': 0.6404015779112127, 'W': 0.33032550440724917}
How does it work?
RankTune is a fairness-tunable ranked data generation method. It constructs a ranking(s) ranking_df by placing items into the constructed ranking from top to bottom. The idea behind RankTune is that to construct a "fair" ranking, each time we place an item in the generated ranking, the likelihood of placing an item in a given group should be equal to that group's proportion of the total items (i.e., if a group is 20% of the item pool, then it should have a 20% chance of being placed). Then, on the other side of the spectrum, if we want a completely "unfair" ranking, we should place items into the rankings such that groups are ordered by increasing size from small to large. In this way, smaller groups get bigger proportions of favorable positions, which violates statistical parity fairness.
To generate rankings along the statistical parity fairness spectrum, RankTune samples a random number in the [0, 1] interval each time it places an item. We design this interval to have "regions" that map to groups. In this way, the unfairness tuning parameter phi controls representativeness, i.e., how fairly each group is represented in the ranking. Specifically, when phi = 1 , then each group is fairly represented. Thus each group's region is equal to the group's proportion of the pool (fair). As phi decreases, the fair representation of each group degrades because regions are distorted in such a way that smaller groups have larger regions compared to their proportion of the total pool (unfair). The fairness tuning parameter phi is used to create the regions prior to placing any items into the generated ranking.
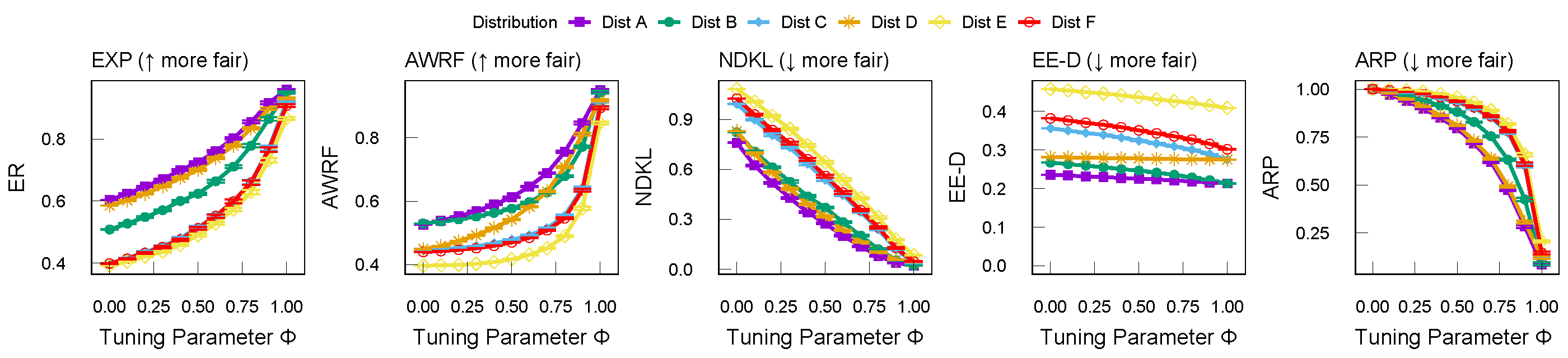
RankTune Demonstration
The figure below displays the results of generating 200 rankings for different phi representativeness values for multiple group distributions. Average metric values (with \(95\%\) confidence intervals) are reported for 200 generated rankings per group distribution of \(1,000\) items. As phi increases, RankTune outputs increasingly fairer rankings. EXP and AWRF are measured with MinMaxRatio combo variables and are more fair at \(1\) (thus upward slopes), and NDKL, EE-D (EXP with an LTwo combo variable ), and ARP (with an MaxMinDiff combo variable) are more fair at \(0\) (thus downward slopes). To learn more, including the group distributions used, please see our technical report.